《机器学习》笔记(第一部分:绪论、模型评估与选择、线性模型)
1 绪论
1.2 基本术语
数据集 D = { x i } i = 1 m D = \{\boldsymbol x_i\}_{i=1}^m D = { x i } i = 1 m m m m d d d X \mathcal X X x i = ( x i j ) j = 1 d \boldsymbol x_i = (x_{ij})_{j=1}^d x i = ( x ij ) j = 1 d d d d X = ∏ i X i \mathcal X = \prod _i \mathcal X_i X = ∏ i X i 注 (feature vector), 其中 x i j x_{ij} x ij x i \boldsymbol x_i x i j j j d d d x i \boldsymbol x_i x i
注 此处的“特征向量”(feature vector) 需要与线性代数中的“特征向量”(eigenvector) 区分.
训 练 从数据中学得模型的过程称为学习 (learning) 或训练 (training). 训练使用的数据称为训练数据 (training data), 单条训练数据称为训练样本 (training sample), 所有训练样本构成训练集 (training set). 训练样本的期待输出称为标记或标签 (label), 拥有标记的示例称为样例 (example). 设 Y \mathcal Y Y ( x i , y i ) (x_i, y_i) ( x i , y i ) i i i y i ∈ Y y_i \in \mathcal Y y i ∈ Y Y \mathcal Y Y ∣ Y ∣ ≤ ℵ 0 |\mathcal Y| \leq \aleph _0 ∣ Y ∣ ≤ ℵ 0 ∣ Y ∣ ≥ ℵ 1 |\mathcal Y| \geq \aleph _1 ∣ Y ∣ ≥ ℵ 1 { ( x i , y i ) } i = 1 m \{(\boldsymbol x_i, y_i)\}_{i=1}^m {( x i , y i ) } i = 1 m f : X → Y f:X\to Y f : X → Y
分类问题 ∣ Y ∣ = 2 |\mathcal Y| = 2 ∣ Y ∣ = 2 Y = B = { + 1 , − 1 } \mathcal Y = \mathbb B = \{+1, -1\} Y = B = { + 1 , − 1 } { 0 , 1 } \{0, 1\} { 0 , 1 }
测 试 学得模型后使用其进行预测的过程叫测试 (testing). 被预测的样本称为测试样本 (testing sample). 学得 f f f x ∗ \boldsymbol x^* x ∗ y ∗ = f ( x ∗ ) y^* = f(\boldsymbol x^*) y ∗ = f ( x ∗ )
无监督学习 分类和回归的训练数据都有标记信息, 属于监督学习 (supervised learning). 聚类 (clustering) 是将训练集中样本分为若干个簇 (cluster) 的算法, 属于无监督学习 (unsupervised learning).
1.3 假设空间
学得的模型对应了关于数据的某种存在规律, 所以模型亦称假设 (hypothesis), 这种潜在规律称为真实 (ground-truth). 我们的目的是寻找与训练集匹配 (fit) 的假设. 所有假设构成的空间 H \mathcal H H L \mathfrak L L X X X h h h
1.4 归纳偏好
版本空间的所有假设在面对测试数据中会各有偏好, 称为归纳偏好 (inductive bias).
设样本空间 X \mathcal X X H \mathcal H H Pr ( h ∣ X , L a ) \Pr(h \mid X, \mathfrak L _a) Pr ( h ∣ X , L a ) L a \mathfrak L _a L a X X X h h h X X X f f f x \boldsymbol x x y y y L \mathfrak L L x ∗ \boldsymbol x^* x ∗
E ( L , x ∗ ∣ X , f ) = ∑ h ( Pr ( h ∣ X , L a ) ⋅ ℓ ( h ( x ∗ ) , f ( x ∗ ) ) ) E(\mathfrak L, \boldsymbol x^* \mid X, f) = \sum _h \bigg(
\Pr(h \mid X, \mathfrak L _a) \cdot
\ell(h(\boldsymbol x^*), f(\boldsymbol x^*))
\bigg) E ( L , x ∗ ∣ X , f ) = h ∑ ( Pr ( h ∣ X , L a ) ⋅ ℓ ( h ( x ∗ ) , f ( x ∗ )) ) 其中 ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ ( ⋅ , ⋅ )
给定训练集 X X X f f f L \mathfrak L L E O T E E _{\rm OTE} E OTE
E O T E ( L ∣ X , f ) = ∑ x ∈ X ∖ X ( Pr ( x ) ⋅ E ( L , x ∣ X , f ) ) E _{\rm OTE}(\mathfrak L \mid X, f) = \sum _{\boldsymbol x \in \mathcal X \setminus X} \bigg(
\Pr(\boldsymbol x) \cdot E(\mathfrak L, \boldsymbol x \mid X, f)
\bigg) E OTE ( L ∣ X , f ) = x ∈ X ∖ X ∑ ( Pr ( x ) ⋅ E ( L , x ∣ X , f ) ) 现在考虑所有可能的真实目标函数 f f f
E = ∑ f ( Pr ( f ) ⋅ E O T E ( L ∣ X , f ) ) \mathcal E = \sum _f \bigg(
\Pr(f) \cdot
E _{\rm OTE}(\mathfrak L \mid X, f)
\bigg) E = f ∑ ( Pr ( f ) ⋅ E OTE ( L ∣ X , f ) ) 没有免费的午餐定理 (NFL 定理, no free lunch theorem) 假设真实目标函数 f f f f f f X → B \mathcal X \to \mathbb B X → B 2 ∣ X ∣ 2^{|\mathcal X|} 2 ∣ X ∣
E = ∑ x ∈ X ∖ X ( Pr ( x ) ⋅ ∑ h ( Pr ( h ∣ X , L a ) ⋅ ∑ f ( Pr ( f ) ⋅ ℓ ( h ( x ) , f ( x ) ) ) ) ) \mathcal E = \sum _{\boldsymbol x \in \mathcal X \setminus X} \Bigg(
\Pr(\boldsymbol x) \cdot \sum _h \bigg(
\Pr(h \mid X, \mathfrak L _a) \cdot \sum _f \Big(
\Pr(f) \cdot
\ell(h(\boldsymbol x), f(\boldsymbol x))
\Big)
\bigg)
\Bigg) E = x ∈ X ∖ X ∑ ( Pr ( x ) ⋅ h ∑ ( Pr ( h ∣ X , L a ) ⋅ f ∑ ( Pr ( f ) ⋅ ℓ ( h ( x ) , f ( x )) ) ) ) 以 ℓ ( y 1 , y 2 ) = 1 y 1 ≠ y 2 \ell(y_1, y_2) = \mathit 1_{y_1 \neq y_2} ℓ ( y 1 , y 2 ) = 1 y 1 = y 2 Pr ( f ) = 1 / 2 ∣ x ∣ \Pr(f) = 1/2^{|\mathcal x|} Pr ( f ) = 1/ 2 ∣ x ∣ f f f f ( x ) = 0 f(\boldsymbol x)=0 f ( x ) = 0 f ( x ) = 1 f(\boldsymbol x)=1 f ( x ) = 1
E = ∑ x ∈ X ∖ X ( Pr ( x ) ⋅ ∑ h ( Pr ( h ∣ X , L a ) ⋅ 1 2 ∣ X ∣ ⋅ 1 2 ⋅ 2 ∣ X ∣ ) ) = 1 2 ∑ x ∈ X ∖ X ( Pr ( x ) ⋅ ∑ h ( Pr ( h ∣ X , L a ) ) ) = 1 2 ∑ x ∈ X ∖ X ( Pr ( x ) ⋅ 1 ) = 1 − Pr ( X ) 2 \begin{aligned}
\mathcal E &= \sum _{\boldsymbol x \in \mathcal X \setminus X} \Bigg(
\Pr(\boldsymbol x) \cdot \sum _h \bigg(
\Pr(h \mid X, \mathfrak L _a) \cdot \frac{1}{2^{|\mathcal X|}} \cdot \frac 12 \cdot 2^{|\mathcal X|}
\bigg)
\Bigg)\\
&= \frac 12 \sum _{\boldsymbol x \in \mathcal X \setminus X} \bigg(
\Pr(\boldsymbol x) \cdot \sum _h \Big(
\Pr(h \mid X, \mathfrak L _a)
\Big)
\bigg)\\
&= \frac 12 \sum _{\boldsymbol x \in \mathcal X \setminus X} \Big(
\Pr(\boldsymbol x) \cdot 1
\Big) = \frac{1 - \Pr(X)}{2}
\end{aligned} E = x ∈ X ∖ X ∑ ( Pr ( x ) ⋅ h ∑ ( Pr ( h ∣ X , L a ) ⋅ 2 ∣ X ∣ 1 ⋅ 2 1 ⋅ 2 ∣ X ∣ ) ) = 2 1 x ∈ X ∖ X ∑ ( Pr ( x ) ⋅ h ∑ ( Pr ( h ∣ X , L a ) ) ) = 2 1 x ∈ X ∖ X ∑ ( Pr ( x ) ⋅ 1 ) = 2 1 − Pr ( X ) 以上计算的结论是: 如果真实的目标函数 f f f E \mathcal E E L \mathfrak L L f f f f f f
2 模型评估与选择
2.2 评估方法
首先需要将数据集 D = { ( x i , y i ) } i = 1 m D = \{(\boldsymbol x_i, y_i)\}_{i=1}^m D = {( x i , y i ) } i = 1 m S S S T T T
留出法 (hold-out) 即把 D = S ∪ T D = S \cup T D = S ∪ T S ∩ T = ∅ S \cap T = \varnothing S ∩ T = ∅ 66 % 66\% 66% 80 % 80\% 80% S S S T T T
交叉验证法 (cross validation) 将 D = ⋃ i = 1 k D i D = \bigcup _{i=1}^k D_i D = ⋃ i = 1 k D i k k k ∀ i , j , D i ∩ D j = ∅ \forall i, j, D_i \cap D_j = \varnothing ∀ i , j , D i ∩ D j = ∅ D i D_i D i k k k k k k k = m k=m k = m ∀ i , ∣ D i ∣ = 1 \forall i, |D_i| = 1 ∀ i , ∣ D i ∣ = 1
自助法 (bootstrapping) 即在数据集 D D D m m m S S S m m m
lim m → ∞ ( 1 − 1 m ) m = e − 1 ≈ 37 % \lim _{m \to \infty} \left(1 - \frac 1m\right)^m = e^{-1} \approx 37\% m → ∞ lim ( 1 − m 1 ) m = e − 1 ≈ 37% 然后取测试集 T = D ∖ S T = D \setminus S T = D ∖ S ∣ S ∣ = m |S| = m ∣ S ∣ = m ∣ T ∣ |T| ∣ T ∣ 37 % 37\% 37%
2.3 性能度量
查准率、查全率与 F β F _\beta F β 考虑分类结果的混淆矩阵 (confusion matrix)
预测正例 预测反例 真实正例 真正例 T P {\rm TP} TP 假反例 F N {\rm FN} FN 真实反例 假正例 F P {\rm FP} FP 真反例 T N {\rm TN} TN
定义查准率 (precision) P P P R R R
P = T P T P + F P , R = T P T P + F N P = \frac{{\rm TP}}{{\rm TP} + {\rm FP}}, \quad
R = \frac{{\rm TP}}{{\rm TP} + {\rm FN}} P = TP + FP TP , R = TP + FN TP 定义 F β F _\beta F β F 1 F _1 F 1 β = 1 \beta = 1 β = 1
F β = ( P − 1 + β 2 R − 1 1 + β 2 ) − 1 , F 1 = ( P − 1 + R − 1 2 ) − 1 F _\beta = \left(
\frac{P ^{-1} + \beta ^2R ^{-1}}{1 + \beta ^2}
\right) ^{-1}, \qquad
F _1 = \left(
\frac{P ^{-1} + R ^{-1}}{2}
\right) ^{-1} F β = ( 1 + β 2 P − 1 + β 2 R − 1 ) − 1 , F 1 = ( 2 P − 1 + R − 1 ) − 1 当 β > 1 \beta > 1 β > 1 F β F _\beta F β β < 1 \beta < 1 β < 1 P P P P P P F β F _\beta F β
对于二分类问题, 一般学习到的模型 g α ∘ f g _\alpha \circ f g α ∘ f f : X → R f: \mathcal X \to \mathbb R f : X → R g α : R → B , z ↦ 1 z > α g _\alpha: \mathbb R \to \mathbb B, z \mapsto \mathit 1 _{z > \alpha} g α : R → B , z ↦ 1 z > α α \alpha α g α ∘ f , ∀ α g _\alpha \circ f, \forall \alpha g α ∘ f , ∀ α { ( P α , R α ) } ∀ α \{(P _\alpha, R _\alpha)\} _{\forall \alpha} {( P α , R α ) } ∀ α ( 0 , 1 ) (0, 1) ( 0 , 1 ) ( 1 , 0 ) (1, 0) ( 1 , 0 )
ROC 曲线与 AUC 定义真正例率 (TPR, true positive rate) 和假正例率 (FPR, false positive rate) 为
T P R = T P T P + F N , F P R = F P T N + F P {\rm TPR} = \frac{{\rm TP}}{{\rm TP} + {\rm FN}}, \quad
{\rm FPR} = \frac{{\rm FP}}{{\rm TN} + {\rm FP}} TPR = TP + FN TP , FPR = TN + FP FP 考虑所有模型 g α ∘ f , ∀ α g _\alpha \circ f, \forall \alpha g α ∘ f , ∀ α { ( F P R α , T P R α ) } ∀ α \{({\rm FPR} _\alpha, {\rm TPR} _\alpha)\} _{\forall \alpha} {( FPR α , TPR α ) } ∀ α ( 0 , 0 ) (0, 0) ( 0 , 0 ) ( 1 , 1 ) (1, 1) ( 1 , 1 )
在离散情况下, 假设 α \alpha α m m m α ( 1 ) , … , α ( m ) \alpha _{(1)}, \dots, \alpha _{(m)} α ( 1 ) , … , α ( m ) α ( i ) \alpha _{(i)} α ( i ) ( F P R ( i ) , T P R ( i ) ) ({\rm FPR} _{(i)}, {\rm TPR} _{(i)}) ( FPR ( i ) , TPR ( i ) )
A U C = ∑ i = 1 m − 1 1 2 ( F P R i + 1 − F P R i ) ( T P R i + T P R i + 1 ) {\rm AUC} = \sum _{i=1} ^{m-1} \frac 12({\rm FPR} _{i+1} - {\rm FPR} _i)({\rm TPR} _i + {\rm TPR} _{i+1}) AUC = i = 1 ∑ m − 1 2 1 ( FPR i + 1 − FPR i ) ( TPR i + TPR i + 1 ) 考虑排序误差. 令 D + , D − D^+, D^- D + , D − f : X → R f: \mathcal X \to \mathbb R f : X → R
ℓ r a n k = 1 ∣ D + ∣ ∣ D − ∣ ∑ x + ∈ D + ∑ x − ∈ D − ( 1 f ( x + ) < f ( x − ) + 1 2 1 f ( x + ) = f ( x − ) ) \ell _{\rm rank} = \frac{1}{|D^+||D^-|} \sum _{\boldsymbol x^+ \in D^+} \sum _{\boldsymbol x^- \in D^-} \Bigg(
\mathit 1 _{f(\boldsymbol x^+) < f(\boldsymbol x^-)} + \frac 12 \mathit 1 _{f(\boldsymbol x^+) = f(\boldsymbol x^-)}
\Bigg) ℓ rank = ∣ D + ∣∣ D − ∣ 1 x + ∈ D + ∑ x − ∈ D − ∑ ( 1 f ( x + ) < f ( x − ) + 2 1 1 f ( x + ) = f ( x − ) ) 即考虑所有正反例两两相配, 若正例预测值小于反例则记 1 1 1 1 / 2 1/2 1/2
A U C = 1 − ℓ r a n k {\rm AUC} = 1 - \ell _{\rm rank} AUC = 1 − ℓ rank 2.4 比较检验
错误率是否等于给定值的 t t t 设某个学习器的真实错误率是 ϵ \epsilon ϵ e ∼ b ( m , ϵ ) e \sim b(m, \epsilon) e ∼ b ( m , ϵ ) { e i } i = 1 k \{e_i\} _{i=1}^k { e i } i = 1 k
H 0 : e = e 0 v.s H 1 : e ≠ e 0 H_0: e = e_0 \quad
\text{v.s} \quad
H_1: e \neq e_0 H 0 : e = e 0 v.s H 1 : e = e 0 它渐进服从正态分布. 考虑它的 t t t
e ˉ = 1 k ∑ i = 1 k e i , s 2 = 1 k − 1 ∑ i = 1 k ( e i − e ˉ ) 2 , t 0 = e ˉ − e 0 σ / k \bar e = \frac 1k \sum _{i=1}^k e_i, \quad
s ^2 = \frac{1}{k-1} \sum _{i=1}^k (e_i - \bar e) ^2, \quad
t_0 = \frac{\bar e - e_0}{\sigma / \sqrt k} e ˉ = k 1 i = 1 ∑ k e i , s 2 = k − 1 1 i = 1 ∑ k ( e i − e ˉ ) 2 , t 0 = σ / k e ˉ − e 0 给定置信度 1 �− α 1 - \alpha 1 − α k − 1 k - 1 k − 1 t t t R ∖ ( − t 1 − α / 2 , t 1 − α / 2 ) \mathbb R \setminus (-t_{1-\alpha/2}, t_{1-\alpha/2}) R ∖ ( − t 1 − α /2 , t 1 − α /2 )
两模型错误率是否相同的交叉验证 t t t 若有两个学习器 A 与 B, 使用 k k k { e i ( A ) } i = 1 k \{e_i^{(A)}\} _{i=1}^k { e i ( A ) } i = 1 k { e i ( B ) } i = 1 k \{e_i^{(B)}\} _{i=1}^k { e i ( B ) } i = 1 k e i ( X ) e_i^{(X)} e i ( X ) i i i Δ e i = e i ( A ) − e i ( B ) \Delta e_i = e_i^{(A)} - e_i^{(B)} Δ e i = e i ( A ) − e i ( B ) t t t
t 0 = Δ e ‾ σ Δ e / n t_0 = \frac{\overline{\Delta e}}{\sigma_{\Delta e} / \sqrt n} t 0 = σ Δ e / n Δ e 两模型是否协同错误的 McNemar 检验 列出两模型的正确率的列联表 (contingency table)
算法 A 正确 算法 A 错误 算法 B 正确 e 00 e _{00} e 00 e 01 e _{01} e 01 算法 B 错误 e 10 e _{10} e 10 e 11 e _{11} e 11
McNemar 检验考虑了以下的统计量, 它是 ∣ e 01 − e 10 ∣ |e_{01} - e_{10}| ∣ e 01 − e 10 ∣
χ 0 2 = ( ∣ e 01 − e 10 ∣ − 1 ) 2 e 01 + e 10 \chi ^2_0 = \frac{(|e_{01} - e_{10}| - 1) ^2}{e_{01} + e_{10}} χ 0 2 = e 01 + e 10 ( ∣ e 01 − e 10 ∣ − 1 ) 2 它服从 χ 2 ( 1 ) \chi^2(1) χ 2 ( 1 ) [ χ 1 − α 2 ( 1 ) , + ∞ ) [\chi^2_{1-\alpha}(1), +\infty) [ χ 1 − α 2 ( 1 ) , + ∞ )
多个模型错误率是否相同的 Friedman 检验与 Nemenyi 后续检验 假设有 k k k { A i } i = 1 k \{A_i\}_{i=1}^k { A i } i = 1 k N N N 1 , … , k 1, \dots, k 1 , … , k { r i } i = 1 k \{r_i\}_{i=1}^k { r i } i = 1 k
χ 0 2 = 12 N k ( k + 1 ) ∑ i = 1 k r i 2 − 3 N ( k + 1 ) \chi ^2_0 = \frac{12N}{k(k+1)} \sum _{i=1}^k r_i^2 - 3N(k+1) χ 0 2 = k ( k + 1 ) 12 N i = 1 ∑ k r i 2 − 3 N ( k + 1 ) 是原始 Friedman 检验统计量, 当 k k k N N N χ 2 ( k − 1 ) \chi^2(k-1) χ 2 ( k − 1 )
F 0 = ( N − 1 ) χ 0 2 N ( k − 1 ) − χ 0 2 F_0 = \frac{(N - 1)\chi^2_0}{N(k - 1) - \chi^2_0} F 0 = N ( k − 1 ) − χ 0 2 ( N − 1 ) χ 0 2 是 Friedman 检验统计量, 当 k k k N N N F ( k − 1 , ( k − 1 ) ( N − 1 ) ) F(k-1, (k-1)(N-1)) F ( k − 1 , ( k − 1 ) ( N − 1 )) [ F 1 − α ( k − 1 , ( k − 1 ) ( N − 1 ) ) , + ∞ ) [F_{1-\alpha}(k-1, (k-1)(N-1)), +\infty) [ F 1 − α ( k − 1 , ( k − 1 ) ( N − 1 )) , + ∞ )
C D = q 1 − α k ( k + 1 ) 6 N {\rm CD} = q_{1-\alpha}\sqrt{\frac{k(k+1)}{6N}} CD = q 1 − α 6 N k ( k + 1 ) 其中 q 1 − α q_{1-\alpha} q 1 − α A i A_i A i A j A_j A j ∣ r i − r j ∣ > C D |r_i - r_j| > {\rm CD} ∣ r i − r j ∣ > CD
2.5 偏差与方差
总体无法被直接观测, 训练集上的预设输出也只是真实输出的观测值. 对于测试样本 x \boldsymbol x x y y y y D y_D y D f ( x , D ) f(\boldsymbol x, D) f ( x , D ) D D D f f f x \boldsymbol x x
取遍所有可能的数据集 D D D f ( ⋅ , D ) f(\cdot, D) f ( ⋅ , D ) x \boldsymbol x x
E f ( x ) = E D f ( x , D ) \mathrm Ef(\boldsymbol x) = \mathrm E _D f(\boldsymbol x, D) E f ( x ) = E D f ( x , D ) 预测方差是
D f ( x ) = E D ( f ( x , D ) − E f ( x ) ) 2 \mathrm Df(\boldsymbol x) = \mathrm E _D (f(\boldsymbol x, D) - Ef(\boldsymbol x)) ^2 D f ( x ) = E D ( f ( x , D ) − E f ( x ) ) 2 期望输出与真实标记的差的平方和称为偏差平方和
b i a s 2 = ( f ˉ ( x ) − y ) 2 {\rm bias}^2 = (\bar f(\boldsymbol x) - y) ^2 bias 2 = ( f ˉ ( x ) − y ) 2 样本标记与真实标记差的平方和称为噪声平方和
ε 2 = E D ( y D − y ) 2 \varepsilon ^2 = \mathrm E _D(y_D - y) ^2 ε 2 = E D ( y D − y ) 2 定义泛化误差平方和是取遍所有可能的数据集 D D D f ( ⋅ , D ) f_(\cdot, D) f ( ⋅ , D )
E ( f ) = E D ( f ( x , D ) − y D ) 2 \mathcal E(f) = \mathrm E _D(f(\boldsymbol x, D) - y_D) ^2 E ( f ) = E D ( f ( x , D ) − y D ) 2 泛化误差平方和可以做如下分解
E ( f ) = b i a s 2 + D ( f ) + ε 2 \mathcal E(f) = {\rm bias} ^2 + \mathrm D(f) + \varepsilon ^2 E ( f ) = bias 2 + D ( f ) + ε 2 即泛化误差平方和可分解为偏差平方和、预测方差与噪声之和.
偏差平方和是预测值与真实值的差值, 刻画算法的拟合能力; 预测方差是不同训练集对预测效果的扰动影响; 噪声是所有学习方法的误差下界. 一般来说偏差和方差是冲突的, 训练不足时偏差大但方差小, 训练充足后训练数据的自身轻微扰动都会发生显著变化.
3 线性模型
3.2 线性回归
线性模型 (linear model) 给定数据集 D = { ( x i , y i ) } i = 1 m D = \{(\boldsymbol x_i, y_i)\} _{i=1}^m D = {( x i , y i ) } i = 1 m x i = ( x i j ) j = 1 d \boldsymbol x_i = (x_{ij}) _{j=1}^d x i = ( x ij ) j = 1 d y i ∈ R y_i \in \mathbb R y i ∈ R
X = ( x 11 ⋯ x 1 d 1 ⋮ ⋮ ⋮ x m 1 ⋯ x m d 1 ) = ( x 1 T 1 ⋮ ⋮ x m T 1 ) , y = ( y 1 ⋮ y m ) X = \begin{pmatrix}
x_{11} & \cdots & x_{1d} & 1\\
\vdots & & \vdots & \vdots\\
x_{m1} & \cdots & x_{md} & 1\\
\end{pmatrix} = \begin{pmatrix}
\boldsymbol x_1^T & 1\\
\vdots & \vdots\\
\boldsymbol x_m^T & 1\\
\end{pmatrix}, \quad
\boldsymbol y = \begin{pmatrix}
y_1\\ \vdots\\ y_m
\end{pmatrix} X = x 11 ⋮ x m 1 ⋯ ⋯ x 1 d ⋮ x m d 1 ⋮ 1 = x 1 T ⋮ x m T 1 ⋮ 1 , y = y 1 ⋮ y m 我们试图学得一个向量 β ∈ R d + 1 = ( w 1 , … , w d , b ) T \boldsymbol \beta \in \mathbb R ^{d+1} = (w_1, \dots, w_d, b)^T β ∈ R d + 1 = ( w 1 , … , w d , b ) T
E = ��∑ i = 1 k ℓ ( β T x i , y i ) = min E = \sum _{i=1}^k \ell(\boldsymbol \beta^T \boldsymbol x_i, y_i) = \min E = i = 1 ∑ k ℓ ( β T x i , y i ) = min 取 ℓ ( x , y ) = ( x − y ) 2 \ell(x, y) = (x - y) ^2 ℓ ( x , y ) = ( x − y ) 2
E = ( y − X β ) T ( y − X β ) E = (\boldsymbol y - X\boldsymbol \beta)^T (\boldsymbol y - X\boldsymbol \beta) E = ( y − X β ) T ( y − X β ) 将其对 β \boldsymbol \beta β
∂ E ∂ β = − 2 X T ( y − X β ) \frac{\partial E}{\partial \boldsymbol \beta} = -2X^T(\boldsymbol y - X\boldsymbol \beta) ∂ β ∂ E = − 2 X T ( y − X β ) 令上式等于零向量, 可以得到 β \boldsymbol \beta β
β = ( X T X ) − 1 X T y \boldsymbol \beta = (X^TX)^{-1}X^T\boldsymbol y β = ( X T X ) − 1 X T y 这个解析解需要 X T X X^TX X T X
广义线性模型 (generalized linear model) 考虑单调可导函数 g ( ⋅ ) g(\cdot) g ( ⋅ )
y = g − 1 ( w T x + b ) y = g^{-1}(\boldsymbol w^T \boldsymbol x + b) y = g − 1 ( w T x + b ) 这是广义线性模型. 其中 g ( ⋅ ) g(\cdot) g ( ⋅ )
3.3 Logistic 回归
令 β = ( w T , b ) T \boldsymbol \beta = (\boldsymbol w^T, b)^T β = ( w T , b ) T x ~ = ( x , 1 ) \tilde{\boldsymbol x} = (\boldsymbol x, 1) x ~ = ( x , 1 ) z = w T x + b = β T x ~ z = \boldsymbol w^T \boldsymbol x + b = \boldsymbol \beta ^T \tilde{\boldsymbol x} z = w T x + b = β T x ~ R \mathbb R R B \mathbb B B g − 1 ( ⋅ ) g^{-1}(\cdot) g − 1 ( ⋅ ) y = 1 z ≥ 0 y = \mathit 1 _{z \geq 0} y = 1 z ≥ 0
y = 1 1 + e − z y = \frac{1}{1 + e^{-z}} y = 1 + e − z 1 将其作为 g − 1 ( ⋅ ) g^{-1}(\cdot) g − 1 ( ⋅ )
y = 1 1 + e − β T x ~ ⟺ ln y 1 − y = β T x ~ y = \frac{1}{1 + e^{-\boldsymbol \beta^T \tilde{\boldsymbol x}}} \iff
\ln \frac{y}{1 - y} = \boldsymbol \beta^T \tilde{\boldsymbol x} y = 1 + e − β T x ~ 1 ⟺ ln 1 − y y = β T x ~ 若将 y y y Y Y Y x \boldsymbol x x
Y 1 − Y , ln Y 1 − Y \frac{Y}{1 - Y}, \qquad \ln\frac{Y}{1 - Y} 1 − Y Y , ln 1 − Y Y 分别称作 Y Y Y Y Y Y Pr ( Y = 1 ∣ x ) \Pr(Y = 1 \mid \boldsymbol x) Pr ( Y = 1 ∣ x )
ln Pr ( Y = 1 ∣ x ) Pr ( Y = 0 ∣ x ) = β T x ~ \ln \frac{\Pr(Y = 1 \mid \boldsymbol x)}{\Pr(Y = 0 \mid \boldsymbol x)} = \boldsymbol \beta^T \tilde{\boldsymbol x} ln Pr ( Y = 0 ∣ x ) Pr ( Y = 1 ∣ x ) = β T x ~ 可以解出来
Pr ( Y = 1 ∣ x ) = e β T x ~ 1 + e β T x ~ , Pr ( Y = 0 ∣ x ) = 1 1 + e β T x ~ \Pr(Y = 1 \mid \boldsymbol x) = \frac{e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}}, \qquad
\Pr(Y = 0 \mid \boldsymbol x) = \frac{1}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}} Pr ( Y = 1 ∣ x ) = 1 + e β T x ~ e β T x ~ , Pr ( Y = 0 ∣ x ) = 1 + e β T x ~ 1 所以给定 x \boldsymbol x x Y Y Y
p ( y ∣ x ) = ( e β T x ~ 1 + e β T x ~ ) y i ⋅ ( 1 1 + e β T x ~ ) 1 − y i p(y \mid \boldsymbol x) = \left(
\frac{e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}}
\right)^{y_i} \cdot \left(
\frac{1}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x}}}
\right)^{1 - y_i} p ( y ∣ x ) = ( 1 + e β T x ~ e β T x ~ ) y i ⋅ ( 1 + e β T x ~ 1 ) 1 − y i 考虑极大似然估计. 已知数据集的情况下, 对数似然函数是
ℓ ( β ) = ∑ i = 1 m ln p ( y i ∣ x i ) = ∑ i = 1 m ( ln ( 1 + e β T x i ~ ) − y i β T x i ~ ) \ell(\boldsymbol \beta) = \sum _{i=1}^m \ln p(y_i \mid \boldsymbol x_i) = \sum _{i=1}^m \Bigg(
\ln(1 + e^{\boldsymbol \beta ^T \tilde{\boldsymbol x_i}}) - y_i \boldsymbol \beta ^T \tilde{\boldsymbol x_i}
\Bigg) ℓ ( β ) = i = 1 ∑ m ln p ( y i ∣ x i ) = i = 1 ∑ m ( ln ( 1 + e β T x i ~ ) − y i β T x i ~ ) 它的梯度和 Hessian 矩阵 分别是
∇ ℓ ( β ) = − ∑ i = 1 m x i ~ ( y i − e β T x i ~ 1 + e β T x i ~ ) , ∇ 2 ℓ ( β ) = ∑ i = 1 m ( x i x i T ⋅ e β T x i ~ 1 + e β T x i ~ ⋅ 1 1 + e β T x i ~ ) \nabla \ell(\boldsymbol \beta) = -\sum _{i=1}^m \tilde{\boldsymbol x_i}\left(
y_i - \frac{e^{\boldsymbol \beta^T \tilde{\boldsymbol x_i}}}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x_i}}}
\right), \qquad
\nabla ^2\ell(\boldsymbol \beta) = \sum _{i=1}^m \left(
\boldsymbol x_i \boldsymbol x_i^T \cdot
\frac{e^{\boldsymbol \beta^T \tilde{\boldsymbol x_i}}}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x_i}}} \cdot
\frac{1}{1 + e^{\boldsymbol \beta^T \tilde{\boldsymbol x_i}}}
\right) ∇ ℓ ( β ) = − i = 1 ∑ m x i ~ ( y i − 1 + e β T x i ~ e β T x i ~ ) , ∇ 2 ℓ ( β ) = i = 1 ∑ m ( x i x i T ⋅ 1 + e β T x i ~ e β T x i ~ ⋅ 1 + e β T x i ~ 1 ) 使用 Newton 法迭代求解极值点, 迭代公式是
β ← β − ( ∇ 2 ℓ ( β ) ) − 1 ∇ ℓ ( β ) \boldsymbol \beta \gets \boldsymbol \beta - \Big(\nabla ^2 \ell(\boldsymbol \beta)\Big) ^{-1} \nabla \ell (\boldsymbol \beta) β ← β − ( ∇ 2 ℓ ( β ) ) − 1 ∇ ℓ ( β ) Logistic 回归也可以理解为是相互独立的 0-1 分布的参数估计, 其待估参数为 β \boldsymbol \beta β
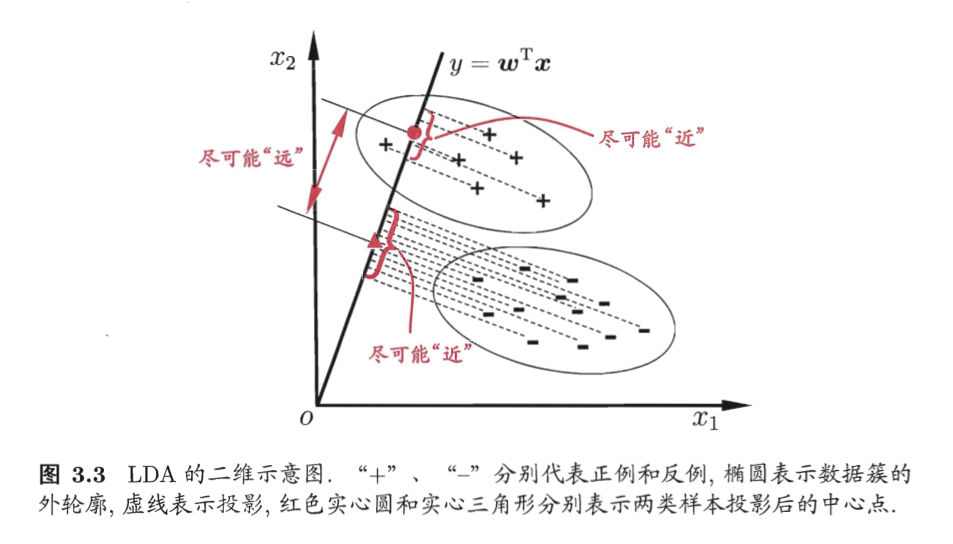
y i ∼ ind p ( β T x ~ i ) y_i \overset{\text{ind}}{\sim} p(\boldsymbol \beta ^T \tilde{\boldsymbol x}_i) y i ∼ ind p ( β T x ~ i ) 3.4 线性判别分析 LDA
假设有一个二分类数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ B D = \{(\boldsymbol x_i, y_i)\} _{i=1}^m, y_i \in \mathbb B D = {( x i , y i ) } i = 1 m , y i ∈ B
将正例和反例分成两个类 X k = { x i : y i = k } , k ∈ B X_k = \{\boldsymbol x_i: y_i = k\}, k\in \mathbb B X k = { x i : y i = k } , k ∈ B μ k = ∑ x ∈ X k x / ∣ X k ∣ \boldsymbol \mu _k = \sum _{\boldsymbol x \in X _k}\boldsymbol x / |X_k| μ k = ∑ x ∈ X k x /∣ X k ∣
s w 2 = ∑ k ∈ B ∑ x ∈ X k ∣ w T ( x − μ k ) ∣ 2 s_{\rm w}^2 = \sum _{k \in \mathbb B} \sum _{\boldsymbol x \in X_k}\Big|
\boldsymbol w ^T (\boldsymbol x - \boldsymbol \mu _k)
\Big| ^2 s w 2 = k ∈ B ∑ x ∈ X k ∑ �� w T ( x − μ k ) 2 是每类中每个点与该类均值距离投影的平方和. 然后考虑刻画类间距离, 考虑
s b 2 = ∣ w T ( μ 0 − μ 1 ) ∣ 2 s_{\rm b}^2 = \Big|\boldsymbol w ^T(\boldsymbol \mu _0 - \boldsymbol \mu _1)\Big| ^2 s b 2 = w T ( μ 0 − μ 1 ) 2 是两类均值点距离投影的平方. 同时考虑二者, 得到优化目标 J = s b 2 / s w 2 = max J = s_{\rm b}^2/s_{\rm w}^2 = \max J = s b 2 / s w 2 = max
现在用方差分析的语言重写这个优化目标. 定义类内散度矩阵 (within-class scatter matrix) 和类间散度矩阵 (between-class scatter matrix)
S w = ∑ k ∈ B ∑ x ∈ X k ( x − μ k ) ( x − μ k ) T , S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_{\rm w} = \sum _{k \in \mathbb B} \sum _{\boldsymbol x \in X _k}(\boldsymbol x - \boldsymbol \mu _k)(\boldsymbol x - \boldsymbol \mu _k) ^T, \qquad
S_{\rm b} = (\boldsymbol \mu _0 - \boldsymbol \mu _1)(\boldsymbol \mu _0 - \boldsymbol \mu _1) ^T S w = k ∈ B ∑ x ∈ X k ∑ ( x − μ k ) ( x − μ k ) T , S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T 再定义全局散度矩阵
S t = ∑ k ∈ B ∑ x ∈ X i ( x − μ ) ( x − μ ) T S_{\rm t} = \sum _{k \in \mathbb B} \sum _{\boldsymbol x \in X_i} (\boldsymbol x - \boldsymbol \mu)(\boldsymbol x - \boldsymbol \mu)^T S t = k ∈ B ∑ x ∈ X i ∑ ( x − μ ) ( x − μ ) T 其中 μ k = ∑ k ∈ B ∑ x ∈ X k x / m \boldsymbol \mu _k = \sum _{k \in \mathbb B} \sum _{\boldsymbol x \in X _k}\boldsymbol x / m μ k = ∑ k ∈ B ∑ x ∈ X k x / m
S t = S w + S b S_{\rm t} = S_{\rm w} + S_{\rm b} S t = S w + S b 于是可以重写优化目标
J = w T S b w w T S w w = max J = \frac{\boldsymbol w ^TS_{\rm b}\boldsymbol w}{\boldsymbol w^TS_{\rm w}\boldsymbol w} = \max J = w T S w w w T S b w = max 即 S b S_{\rm b} S b S w S_{\rm w} S w w \boldsymbol w w w T S w w = 1 \boldsymbol w^TS_{\rm w}\boldsymbol w = 1 w T S w w = 1
max w w T S b w s.t. w T S w w = 1 \begin{aligned}
\max _{\boldsymbol w} \quad & \boldsymbol w^TS_{\rm b}\boldsymbol w\\
\text{s.t.} \quad & \boldsymbol w^TS_{\rm w}\boldsymbol w = 1
\end{aligned} w max s.t. w T S b w w T S w w = 1 使用 Lagrange 乘子法. 它的 Lagrange 函数是
L ( w , λ ) = − w T S b w + λ ( w T S w w − 1 ) \mathcal L(\boldsymbol w, \lambda) = -\boldsymbol w^TS_{\rm b}\boldsymbol w + \lambda (\boldsymbol w^TS_{\rm w}\boldsymbol w - 1) L ( w , λ ) = − w T S b w + λ ( w T S w w − 1 ) 令导数为零
∂ L ∂ w = − 2 S b w + 2 λ S w w = 0 ⟹ S b w = λ S w w \frac{\partial \mathcal L}{\partial \boldsymbol w} = -2S_{\rm b}\boldsymbol w + 2\lambda S_{\rm w}\boldsymbol w = 0 \implies
S_{\rm b}\boldsymbol w = \lambda S_{\rm w}\boldsymbol w ∂ w ∂ L = − 2 S b w + 2 λ S w w = 0 ⟹ S b w = λ S w w 我们只要得到其中一组解就可以了. 注意到
S b w = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w S_{\rm b} \boldsymbol w = (\boldsymbol \mu _0 - \boldsymbol \mu _1)(\boldsymbol \mu _0 - \boldsymbol \mu _1) ^T \boldsymbol w S b w = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w 这启发我们令 λ = ( μ 0 − μ 1 ) T w \lambda = (\boldsymbol \mu _0 - \boldsymbol \mu _1) ^T \boldsymbol w λ = ( μ 0 − μ 1 ) T w
S b w = λ ( μ 0 − μ 1 ) S_{\rm b} \boldsymbol w = \lambda (\boldsymbol \mu _0 - \boldsymbol \mu _1) S b w = λ ( μ 0 − μ 1 ) 代入 S b w = λ S w w S_{\rm b}\boldsymbol w = \lambda S_{\rm w}\boldsymbol w S b w = λ S w w
w = S w − 1 ( μ 0 − μ 1 ) , λ = ( μ 0 − μ 1 ) T w \boldsymbol w = S_{\rm w}^{-1}(\boldsymbol \mu _0 - \boldsymbol \mu _1), \quad
\lambda = (\boldsymbol \mu _0 - \boldsymbol \mu _1) ^T \boldsymbol w w = S w − 1 ( μ 0 − μ 1 ) , λ = ( μ 0 − μ 1 ) T w 在多分类问题中 k ∈ { 1 , … , N } k \in \{1, \dots, N\} k ∈ { 1 , … , N } B \mathbb B B
S w k = ∑ x ∈ X k ( x − μ k ) ( x − μ k ) T , S w = ∑ k S w k , S b = ∑ i = 1 N ∣ X i ∣ ( μ i − μ ) ( μ i − μ ) T S_{{\rm w}k} = \sum _{\boldsymbol x \in X _k}(\boldsymbol x - \boldsymbol \mu _k)(\boldsymbol x - \boldsymbol \mu _k) ^T, \quad
S_{\rm w} = \sum _k S_{{\rm w}k}, \qquad
S_{\rm b} = \sum _{i=1}^N|X_i|(\boldsymbol \mu _i - \boldsymbol \mu)(\boldsymbol \mu _i - \boldsymbol \mu)^T S w k = x ∈ X k ∑ ( x − μ k ) ( x − μ k ) T , S w = k ∑ S w k , S b = i = 1 ∑ N ∣ X i ∣ ( μ i − μ ) ( μ i − μ ) T 此时优化问题为
max W ∈ R d × ( N − 1 ) t r W T S b W t r W T S w W \max _{W \in \mathbb R ^{d \times (N-1)}} \frac{\mathop{\rm tr}W^TS_{\rm b}W}{\mathop{\rm tr}W^TS_{\rm w}W} W ∈ R d × ( N − 1 ) max tr W T S w W tr W T S b W 该问题可化为广义特征值问题
S b W = λ S w W S_{\rm b}W = \lambda S_{\rm w}W S b W = λ S w W 组合其前 N − 1 N-1 N − 1 W W W
3.5 多分类问题
本节研究如何将二分类问题推广至多分类. 使用拆解法, 将多分类问题拆解为若干个二分类问题. 假设数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ { C 1 , … , C N } D = \{(\boldsymbol x_i, y_i)\} _{i=1}^m, y_i \in \{C_1, \dots, C_N\} D = {( x i , y i ) } i = 1 m , y i ∈ { C 1 , … , C N }
一对一 (OvO, one vs one), 每次将其中一类作为正例、另外其中一类作为反例, 拆解为 O ( N 2 ) O(N^2) O ( N 2 ) O ( m / N ) O(m/N) O ( m / N )
一对其余 (OvR, one vs rest), 每次将其中一类作为正例、其它所有类作为反例, 拆解为 O ( N ) O(N) O ( N ) ( m ) (m) ( m )
多对多 (MvM, many vs many), 每次将若干类作为正例、其他所有类作为反例, 正反例构造必须有特殊设计, 不能随意选取.
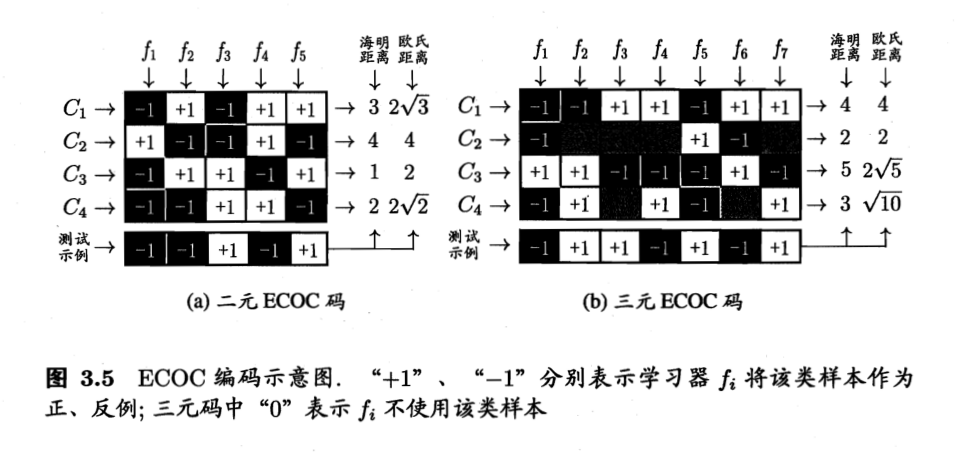
纠错输出码 (ECOC, error correcting output codes) 是一种常见的 MvM 技术. 预设分�类器数量 M M M C i C_i C i C i ∈ B M \boldsymbol C_i \in \mathbb B ^M C i ∈ B M C ∗ \boldsymbol C^* C ∗ C i \boldsymbol C_i C i
3.6 类别不平衡问题
有时正例数量远远少于反例. 解决类别不平衡问题的常见方法有三种:
欠采样 (undersampling), 即舍弃一些反例;
过采样 (oversampling), 即增加一些正例;
阈值移动 (threshold-moving).
�阈值移动的一个基本策略是再缩放 (rescaling). 例如线性分类器考虑了 y / ( 1 − y ) > 1 y / (1 - y) > 1 y / ( 1 − y ) > 1 ∣ X 1 ∣ / ∣ X 0 ∣ |X_1| / |X_0| ∣ X 1 ∣/∣ X 0 ∣ 1 1 1
本系列的参考文献
[1] 周志华. 机器学习[M]. 清华大学出版社, 2016.
[2] 谢文睿, 秦州, 贾彬彬. 机器学习公式详解[M]. 人民邮电出版社, 2023.