《机器学习》笔记(第二部分:决策树、神经网络、支持向量机)
4 决策树
4.1 基本流程
假设数据集 D={(xi,yi)}i=1m, xi=(xij)j=1d, 属性序号集 A={a}a=1d.
问题: 生成一棵树. 深度为 d+1, 其中根节点和中间节点共 d 层, 结果叶节点 1 层. 每个根 (中间) 节点是一个决策: 属性 a∗ 的值是多少? 根据其取值, 确定下一轮进入的子节点. 从根节点往下判断, 共经过 d 个节点, 恰好是全部 d 个属性的问题.
- 函数 generate_tree(D, A)
- 输入:
- 训练集 D={(xi,yi)}i=1m
- 属性序号集 A={a}a=1d
- 过程:
- 生成节点 node
if y1=y2=⋯=ym- 将 node 标记为叶节点, 其类别为 y1
if x1=x2=⋯=xm- 将 node 标记为叶节点, 其类别为 {yi} 的众数
- 从 A 中选择一个最优划分属性 a∗
for a∗ 的每一种可能取值 v- 为 node 生成一个分支节点 subnode
- 令 Dv 表示 D 中在 a∗ 取值为 v 的样本子集
-
if Dv=∅
- 将 subnode 标记为叶节点, 其类别为 {yi} 的众数
-
else
- 令 subnode 为 generate_tree(Dv, A∖{a∗})
这样可以生成一个深度最多为 d+1 的树.
4.2 划分选择
问题: 在当前给定的数据集 D 和属性集 A 下, 在当前节点 node 处, 应该选择哪一个属性作为最优划分属性? 选定优化目标: 我们希望每个 subnode 所包含的样本, 尽可能属于同一类别. 即纯度 (purity) 越来越高.
信息熵 对于这个问题, Shannon 已经给了我们答案. 对于数据集 D, 定义信息熵 (information entropy)
EntD:=−y∈Y∑pylbpy
其中 Y 是标记集, py 表示标记值为 y 的样本占整个 D 的比例. 约定 0lb0=0. 它的取值范围是
0≤EntD≤lb∣Y∣
我们的目的是降低信息熵: 信息熵越小, D 的纯度越高.
信息增益 给定属性 a∗, 考虑划分前与划分后信息熵之差 (加权)
GainDa∗:=EntD−v∈Xa∗∑∣D∣∣Dv∣EntDv
其中 v 取遍属性 a∗ 的所有可能取值, Dv 表示 D 中在 a∗ 取值为 v 的样本子集. 上面的差式定义为信息增益 (information gain). 差式越大, 说明 a∗ 在划分 D 式造成的信息熵减少越多. 故取
a∗=argmaxa∈AGainDa
作为划分属性即可.
增益率 信息增益有一个漏洞, 它偏好取值种类较多的属性. 作为一个修正, 定义增益率 (gain ratio)
GainRatioDa:=IVDaGainDa,IVDa:=−v∈Xa∗∑∣D∣∣Dv∣lb∣D∣∣Dv∣
其中 IVDa 是属性 a 在训练集 D 上的固有值 (intrinsic value). 增益率偏好取值种类较少的属性.
基尼指数 基尼指数 (Gini index) 反映了数据集中任取两个样本, 其类别标记不一致的概率. 定义基尼值 (Gini value)
GiniD:=y,y′∈Yy=y′∑pypy′=1−y∈Y∑py2
基尼指数越小, 数据集纯度越高. 定义基尼指数
GiniIndexDa:=v∈Xa∗∑∣D∣∣Dv∣GiniDv
取基尼指数最小的那个属性
a∗=argmina∈AGiniIndexDa
作为划分属性即可.
4.3 剪枝处理
完整的、将每一个属性都完全划分的决策树, 很容易出现过拟合问题. 对于每一个节点 node, 比较剪枝前 (即 node 是有分支的节点) 和剪枝后 (即将 node 置为叶子结点), 决策树在验证集 T 的预测精度, 来决定是否要进行剪枝操作.
预剪枝 在生成决策树时, 若当前节点 node 划分后比划分前预测精度低, 则将 node 置为叶节点. 其类别为 yi 的众数. 预剪枝是基于贪心思想设计, 容易欠拟合.
后剪枝 在生成完决策树后, 从叶节点往上逐个判断. 若节点 node 划分后精度反低, 则置为叶节点. 后剪枝有效规避了欠拟合问题, 但是计算开销较大.
4.4 连续与缺失值
4.4.1 连续值处理
研究属性 a∈A 是连续值的情况, 即 Xa 是连续的. 基本思想是将属性 a 通过阈值 t∈R 分为正反两类. 假设样本集 D 在属性 a 上有 n 个取值 {v(i)}i=1n (从小到大排序), 从以下集合中选取阈值 t
t∈T={2v(i)+v(i+1)}i=1n−1
选取后, 按照样本在属性 a 上取值大于 t 和小于 t 分为两个集合, 记为
D=D+∪D−,D+∩D−=∅
该属性的增益值为取遍所有可能的 t 造成的增益的最大值, 即
GainDa∗:=EntD−∣D∣∣D+∣EntD+−∣D∣∣D−∣EntD−
需要注意的是, 若当前划分属性是连续属性, 则该属性还可作为其后代节点的划分属性. 此时树的深度可能大于 d+1.
4.4.2 缺失值处理
研究属性 a∈A 有缺失值的情况. 首先考虑如何选择�划分准则. 记 D~ 为属性 a 没有缺失值的样本子集, D~v 为 D~ 中在属性 a 取值 v 的样本子集. 为每一个样本 xi 赋予一个初始权重 wi=1. 定义
ρ:=i=1xi∈D~∑nwi/i=1∑nwi,rv:=i=1xi∈D~v∑nwi/i=1xi∈D~∑nwi
ρ 表示无缺失值样本占比; rv 表示无缺失样本中属性 a 的值为 v 的样本占比. 信息增益推广为
GainDa:=ρ(EntD~−v∈Xa∑rvEntD~v)
再考虑选定划分属性 a 后如何对样本进行划分. 若 xia 已知, 则正常生成节点并将 xi 放入该节点. 若 xia 缺失, 则将 xi 同时划入所有子节点, 且样本权值在属性值为 v 的子节点中调整为 rvwi. 这是将 xi 以不同概率分入不同子节点中.
4.5 多变量决策树
前面说的是单变量决策树, 即每一节点只根据一个属性的值分类, 分类边界在图上画出来是与坐标轴平行的折线段. 多变量决策树 (multivariate decision tree) 的节点根据多个属性的线性组合的值分类, 这样可以形成斜的分类边界.
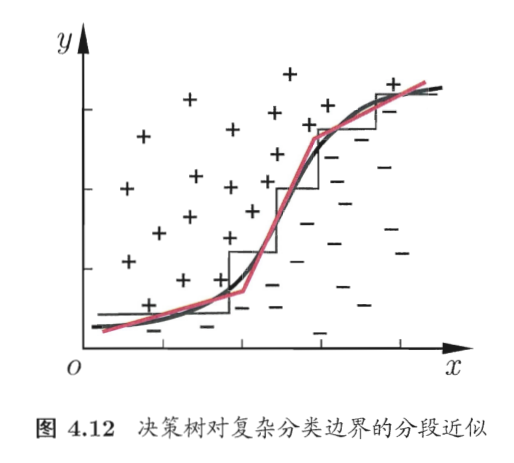
5 神经网络
5.1 神经元模型
神经元 (neuron) 是神经网络的基本单位. 它由 n 个输入 {xi}i=1n、n 个权重 {wi}i=1n、一个阈值 (threshold) θ∈R 和一个激活函数 (activation function) f:R→R 计算输出 y
y=f(i=1∑nwixi−θ)
其中激活函数 f 有一些常见取法, 例如阶跃函数
f:R→{0,1},x↦1x≥0
例如 ReLU 函数
f:R→[0,+∞),x↦1x≥0⋅x
再例如 Sigmoid 函数
f:R→(0,1),x↦1+e−x1
Sigmoid 函数是可导的. 它的导数是
f′(x)=f(x)(1−f(x))
5.2 感知机
感知机 (perceptron) 就是 2 层共 n+1 个神经元构成的神经网络: 输入层 (n 个神经元) 和输出层 (1 个神经元). 取激活函数为阶跃函数 f(x)=1x≥0, 输出 y 与输入 {xi}i=1n 的对应关系是
y=f(i=1∑nwixi−θ)={1,0,∑wixi≥θ,∑wixi<θ
这在几何上等价于在 Rn 中用一个 n−1 维超平面将全空间分割为两部分, 一部分输出为 1 而另一部分为 0, 以此实现分类功能.
记 y 是真实值, y^=f(∑wixi−θ) 是预测值. 定义损失函数
L(w1,…,wn,θ)=(y^−y)(i=1∑nwixi−θ)
这是一个合理的损失函数, 因为正确分类点损失为 0; 错误分类点��损失为正, 且与该点与超平面的距离正相关. 现在进行简化, 令 wn+1=θ 和 xn+1=−1, 即定义一个固定输入为 −1 的哑结点 (dummy node). 此时损失函数简化为
L(w1,…,wn,wn+1)=(y^−y)i=1∑n+1wixi=(y^−y)wTx
其中 w=(wi)i=1n+1 是权值向量, x=(xi)i=1n+1 是输入向量.
现在建立基于梯度下降的优化方法. 感知机使用随机梯度下降法: 每次随机选取一个误分类点 (x,y) 并进行下降. 求损失函数�的梯度
∇L(w)=(y^−y)x
得到梯度下降的更新式
w←w+Δw,Δw=−η(y^−y)x
其中学习率 (learning rate) η∈(0,1) 是一个预设参数. 重复迭代直到收敛即可.
感知机只有一层功能神经元 (functional neuron), 只可以处理线性可分 (linearly separable) 的问题. 处理更复杂的问题需要使用多层网络.
5.3 多层网络与误差逆传播算法
5.3.1 信号的前向传播
假设一个包含 1 个�隐藏层 (hidden layer) 的神经网络. 给定训练集 D={(xi,yi)}i=1m,xi∈Rd,yi∈Rℓ, 注意这里输入和输出都是向量.
约定符号:
- 输入层:
- 有 d 个神经元;
- 第 i 个神经元的输入是 xi.
- 输入层第 i 个神经元至隐藏层第 h 个神经元的连接权重是 vih;
- 隐藏层:
- 有 q 个神经元;
- 第 h 个神经元的输入是 αh, 阈值是 γh, 输出是 bh.
- 隐藏层第 h 个神经元至输出层第 j 个神经元的连接权重是 wih;
- 输出层:
- 有 ℓ 个神经元;
- 第 j 个神经元的输入是 βj, 阈值是 θj, 输出是 yj.
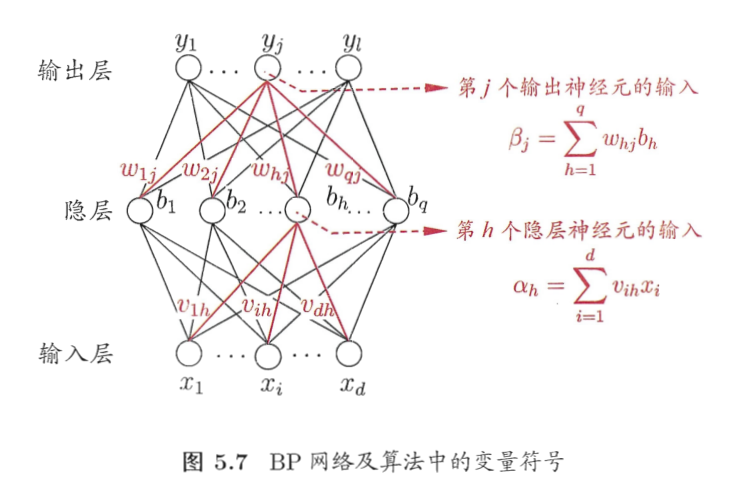
它们的联系是:
αh=i=1∑dvihxi,bh=f(αh−γh)
以及
βj=h=1∑qwhjbh,yj=f(βj−θj)
该神经网络的参数有
W={vih}i≤d,h≤q∪{γh}h≤q∪{whj}h≤q,j≤ℓ∪{θj}j≤ℓ
共 (d+1)q+(q+1)j 个.
5.3.2 误差的反向传播
以均方误差作为优化目标:
E=21∣∣y^−y∣∣22=min
选定 f 是 Sigmoid 函数, 对 whj 求导:
∂whj∂E=∂y^j∂E⋅∂βj∂y^j⋅∂whj∂βj
定义输出层神经元的梯度 gj
gj:=−∂y^j∂E⋅∂βj∂y^j=(y^j−yj)⋅y^j(1−y^j)
于是有
Δwhj=−η∂whj∂E=ηgjbh
类似可得
Δθj=−ηgj,Δvih=ηehxi,Δγh=−ηeh
其中隐藏层神经元的梯度 eh
eh:=−∂bh∂E⋅∂αh∂bh=(j=1∑ℓwhjgj)⋅bh(1−bh)
所有的导数都有显式解.
误差逆传播 (error backpropagation) 算法流程如下:
- 输入:
- 训练集 D={(xk,yk)}k=1m
- 超参数:
- 过程:
- 随机生成权值和阈值的初值 whj,θj,vih,γh∈(0,1)
do until 收敛或达到最大迭代次数-
for each (x,y)∈D do
- 根据当前参数计算输出 y (信号的前向传播)
- 计算输出层神经元梯度 gj
- 计算隐藏层神经元梯度 eh
- 更新权值和阈值 whj,θj,vih,γh (误差的反向传播)
多层神经网络可以拟合任意复杂的连续函数, 但是常遭遇过拟合. 常用的有两种方法: 一是早停 (early stopping), 即若训练集误差降低但验证集误差升高则停止训练; 二是正则化 (regularization), 即误差函数同时考虑误差的大小和权值的大小
E~=λE+(1−λ)w∈W∑w2
其中 w 取遍所有权值和阈值.
6 支持向量机 SVM
6.1 间隔与支持向量
给定训练样本集 D={(xi,yi)}i=1m,x∈Rn,yi∈B. 寻找一个超平面 ℓ:wTx+b=0, 使得超平面的分类效果最好.
考虑两个超平面, 将全空间分为三个部分:
- ℓ+:wTx+b=+1, 所有正例在其之外, 最近的正例在其之上 (称为正支持向量);
- ℓ−:wTx+b=−1, 所有反例在其之外, 最近的反例在其之上 (称为反支持向量);
- ℓ+ 与 ℓ− 之间有距离为 γ=2/∣w∣ 无样例区域.
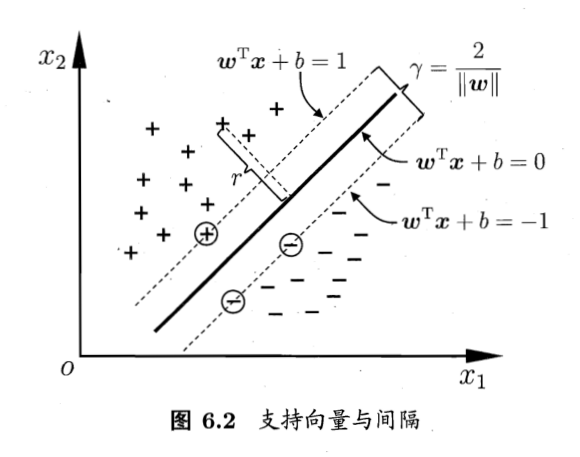
即是说在
{wTxi+b≥+1,wTxi+b≤−1,yi=+1yi=−1
的条件下使得间隔最大
maxγ=∣w∣2⟺min21∣w∣2
所以支持向量机的优化目标是
w,bmins.t.21∣w∣2yi(wTxi+b)≥1,∀i
6.2 对偶问题
考虑 Lagrange 乘子法. 它的 Lagrange 函数是
L(w,b,α)=21∣w∣2+i=1∑mai(1−yi(wTx+b))
其中 α=(α1,…,αm) 是 Lagrange 乘子. αi>0,∀i.
Lagrange 乘子法就是将求目标函数条件最值的问题转化为求 Lagrange 函数全局最值的问题. 现求解 maxL: 对 w 和 b 求导并令导数为 0 和 0, 得到
i=1∑mαiyixi=w,i=1∑mαiyi=0
将第一式代入 Lagrange 函数可消去 w 和 b
L=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
将 Lagrange 乘子看做自变量, 得到一个仅关于 αi 的对偶问题
αmaxs.t.i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=0,αi≥0,∀i
KKT 条件是最优化问题的必要条件. 据其有
∀i,αi=0∨yi(wTxi+b)=1
所以样本点 (xi,yi) 要么对划分超平面的选取没有影响 (因为 αi=0 而 w=∑αiyixi); 要么在 ℓ+ 或 ℓ− 上, 此时该样本点是支持向量. 亦即划分平面的选取仅与支持向量有关.
上面的最优化问题有 m 个待求解变量 αi, 自由度为 m−1. 求解使用 SMO (Sequential Minimal Optimization) 算法求解:
- 选取一对样本 (xi,yi),(xj,yj), 一般使用违背 KKT 条件程度最大的一对样本;
- 固定 αi 和 αj 以外的其它参数, 求解上面的最优化问题 (此时已简化为一个一元二次最值问题), 更新 αi,αj 的值;
- 不断重复上述两步直到收敛.
在获得所有 αi 的值后, 就可以确定 w=∑αiyixi 以及 b=ys−∑αiyixiTxs, 其中 s 取任意支持向量 (xs,ys).
6.3 核函数
有定理表明: 若样本维数 d<∞, 则存在一个升维的函数 φ:Rd→Rd′(d′>d), 使得映射后的样本集 D′={(φ(xi),yi)}i=1m 是线性可分的. 希望找到一个超平面 wTφ(x)+b=0. 优化问题是
w,bmins.t.21∣w∣2yi(wTφ(xi)+b)≥1,∀i
对偶问题是
αmaxs.t.i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjφ(xi)Tφ(xj)i=1∑mαiyi=0,αi≥0,∀i
其中 φ(xi)T�φ(xj) 是 φ:Rd→Rd′ 与 (⋅)T(⋅):Rd′×Rd′→R 的复合. 为了规避 d′ 维空间, 定义这个复合为核函数 (kernel function) κ:Rd×Rd→R. 对于核函数的选取有如下定理:
核函数定理 给定数据集 D={xi}i=1m, 对称函数 κ:Rd×Rd→R 是核函数当且仅当其核矩阵 (kernel matrix) 半正定.
K:=κ(x1,x1)⋮κ(xm,x1)⋯⋱⋯κ(x1,xm)⋮κ(xm,xm)⪰0
核函数的选择对支持向量机的性能至关重要. 常见的核函数有:
| 核函数 | 表达式 | 参数 |
|---|
| 线性核 | κ(xi,xj)=xiTxj | - |
| 多项式核 | κ(xi,xj)=(xiTxj)d | d≥1 是多项式次数 |
| RBF (Gauss) 核 | κ(xi,xj)=exp−∥xi−xj∥2/2σ2 | σ>0 是 Gauss 核的带宽 (width) |
| Laplace 核 | κ(xi,xj)=exp−∥xi−xj∥/σ | σ>0 |
| Sigmoid 核 | κ(xi,xj)=tanh(βxiTxj−�θ) | β>0,θ>0 |
此外, 核函数还可以通过组合得到.
- 核函数的线性组合是核函数;
- 核函数的积是核函数;
- 对于核函数 κ 和任意函数 g(⋅), g(xi)κ(xi,xj)g(xj) 是核函数.
6.4 软间隔与正则化
求解划分平面时, 可以不要求所有样本都划分正确. 称为划分可以具有软间隔 (soft margin). 在优化目标中加入一个惩罚项:
w,bmin21∣w∣2+C⋅i=1∑mℓ(yi(wTxi+b)−1)
其中 ℓ(z)=1z<0 是惩罚函数. 惩罚函数也可以选择其它函数, 例如 hinge 损失:
ℓ(z)=max(0,1−z)
此时优化问题可以重写为
w,b,ξmins.t.21∣w∣2+Ci=1∑mξiyi(wTxi+b)≥1−ξi,ξi≥0,∀i
其中 ξ 称为松弛变量 (slack variables), 它是一个中间变量. 该问题的 Lagrange 函数是
L(w,n,α,ξ,μ)=21∣w∣2+Ci=1∑mξi+i=1∑mαi(1−ξi−yi(wTxi+b))−i=1∑mμiξi
其中 αi≥0,μi≥0 是 Lagrange 乘子. 对 w,b,ξ 求偏导并令其为零
i=1∑mαiyixi=w,i=1∑mαiyi=0,α+μ=C⋅1
它的对偶问题是
αmaxs.t.i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=0,αi≥0≥C,∀i
比硬间隔多出一条 αi≤C 的限制, 可以用相同算法求解. 它的 KKT 条件中要求
αi=0∨yi(wTx+b)−1+ξi=0,μi=0∨ξi=0
即样本 i 一方面要么对划分平面选取无影响, 要么是支持向量; 若是支持向量, 要么在两条最大间隔边界上 (ξi=0), 要么在最大间隔边界之间 (μi=0∧0<ξ≤1) 或者被错误分类 (μi=0∧ξ>1).
假设划分超平面以 f(x,θ)=0 的方程形式给出, 其中 x 是自变量, θ 是参数. 假设划分的超平面的间隔是 Ω(θ), 样本 (xi,yi) 造成的惩罚是 ℓ(f(xi),yi). 此时优化目标是
θminΩ(θ)+C⋅i=1∑mℓ(f(xi),yi)
其中 Ω(θ) 称为结构风险 (structural risk), 与模型本身有关; ∑ℓ(f(xi),yi) 称为经验风险 (empirical risk), 与模型同训练数据的契合程度有关.
正则化 (regularization) 是一个机器学习术语, 指在原始�模型中引入额外信息, 以防止过拟合并提高泛化性能. Ω(θ) 称为正则化项, C 称为正则化常数. Lp 范数是常用的正则化项: L2 范数倾向平衡各分量取值, L1 与 L0 范数倾向减少非零分量个数.
6.5 支持向量回归 SVR
支持向量机除了可用于分类, 还可用于回归. 给定训练样本 D={(xi,yi)}, 考虑岭回归
w,bmin21∣w∣2+Ci=1∑mℓ(yi−(wTx+b))
一般的最小二乘回归取损失函数 ℓz=z2. 支持向量回归中的损失函数取 ε-不敏感损失:
ℓε(z)={0,∣z∣−ε,∣z∣≤ε,otherwise
即回归误差在 ±ε 以内时, 认为误差为零. 以外时, 按线性损失计. 引入松弛变量 ξ^,ξ, 问题可以重写为
w,b,ξ^,ξmins.t.21∣w∣2+Ci=1∑m(ξi+ξ^i)−(ε+ξi)≤yi−(wTx+b)≤ε+ξ^iξ^i≥0,ξi≥0,∀i
它的 Lagrange 函数是
L(w,b,α,α^,ξ,ξ^,μ,μ^)=21∣w∣2+Ci=1∑m(ξi+ξ^i)−i=1∑mμiξi−i=1∑mμ^iξ^i+i=1∑mαi((wTx+b)−yi−ε−ξi)+i=1∑mα^i(yi−(wTx+b)−ε−ξ^i)
其中 αi≥0,α^i≥0,μi≥0,μ^i≥0 是 Lagrange 乘子. 对 w,b,ξ,ξ^ 求偏导并令其为零
i=1∑m(α^i−αi)xi=w,i=1∑m(α^i−αi)=0,α+μ=α^+μ^=C⋅1
它的对偶问题是
α,α^maxs.t.i=1∑myi(α^i−αi)−ε(α^i+αi)−21i=1∑mj=1∑m(α^i−αi)(α^j−αj)xiTxji=1∑m(α^i−αi)=0,0≤αi≤C,0≤α^i≤C,∀i
它的 KKT 条件表明 αi 和 α^i 至少有一个为零. 两个都为零则说明样本落在 ε-间隔带内. 因为 w∑(α^i−αi)xi, 所以回归结果仅与间隔带以外的样本有关.
若考虑核函数形式, 则相应的解为
w=i=1∑m(α^i−αi)κ(xi,x)
其中 κ(⋅,⋅) 是核函数.
6.6 核方法
SVM 和 SVR 的结果总能表示成核函数 κ(xi,x) 的线性组合. 这一结论不是巧合, 因为有如下定理:
核函数表示定理 令 ∣⋅∣ 表示某种范数, 给定核函数 κ(⋅,⋅), 在增函数 Ω(⋅) 和损失函数 ℓ(⋅) 下, 优化问题
fminΩ(∣h∣)+ℓ(f(x1),⋅,f(xm))
的解总可以写成
f∗(x)=i=1∑mαiκ(xi,x)
的形式.
引入核函数称为核方法 (kernel methods) 可以将线性算法扩展到非线性. �以线性判别分析 LDA 为例, 尝试引入核线性判别分析 KLDA. 考虑一个映射 φ:X→F 将样本映射到特征空间 F. 在 F 上求一条直线 w, 使得点 x 在其上的投影
h(x)=wTφ(x)
优化目标是
wmaxJ(w):=wTSwwwTSbw
其中 Sb,Sw 分别是样本映射到 F 后的类间散度矩阵和类内散度矩阵
Sb:=(μ1−μ0)(μ1−μ0)T,Sw:=i∈B∑x∈Xi∑(φ(x)−μi)(φ(x)−μi)T
其中类均值 μi:=∑x∈Xiφ(x)/∣Xi∣. 定义核函数 κ(xi,x):=φ(xi)Tφ(x).
优化目标 J(w) 满足核函数表示定理的目标函数形式, 所以 ∃α 使得
h∗(x)=i=1∑mαiκ(xi,x)⟺w∗=i=1∑mαiφ(xi)
现在考虑求解 α. 定义 K=(κ(xi,xj))m×m 是核矩阵. 令 1i∈{0,1}m 是第 i 类样本的指示向量, 1i 的第 j 个分量为 1 当且仅当 xj∈Xi, 否则为 0. 然后令
μ^i:=∣Xi∣K1i,M:=(μ^1−μ^0)(μ^1−μ^0)T,N:=KKT−i∈B∑∣Xi∣μ^iμ^iT
此时优化目标变为
αmaxJ=αTNααTMα
这是 M 与 N 的广义 Rayleigh 商, 根据线性判别分析的求解方法求解即可.